这是小米第一次参与到大模型开源社区中,也许考虑先发个小模型练练手而已吧,看起来还没摸透大模型宣发的套路,毕竟连ollama都没上,Huggingface space都没。昨天隔壁Qwen上线模型,ollama版本都是同步上线,Huggingface space都是马上能用的。
既然你米还没做space应用,那么我先帮你做个吧。我在Huggingface space上创建了基于MiMo-7B-RL的应用,大家可以测试一下。
(花了我9刀开通Huggingface pro,希望雷总给我报销)
总体来说,我觉得这是一个偏科比较严重的小模型。
我就说了「你好」,竟然直接给我写代码了。服了
不过很正常,毕竟是针对数学和编程优化过的。
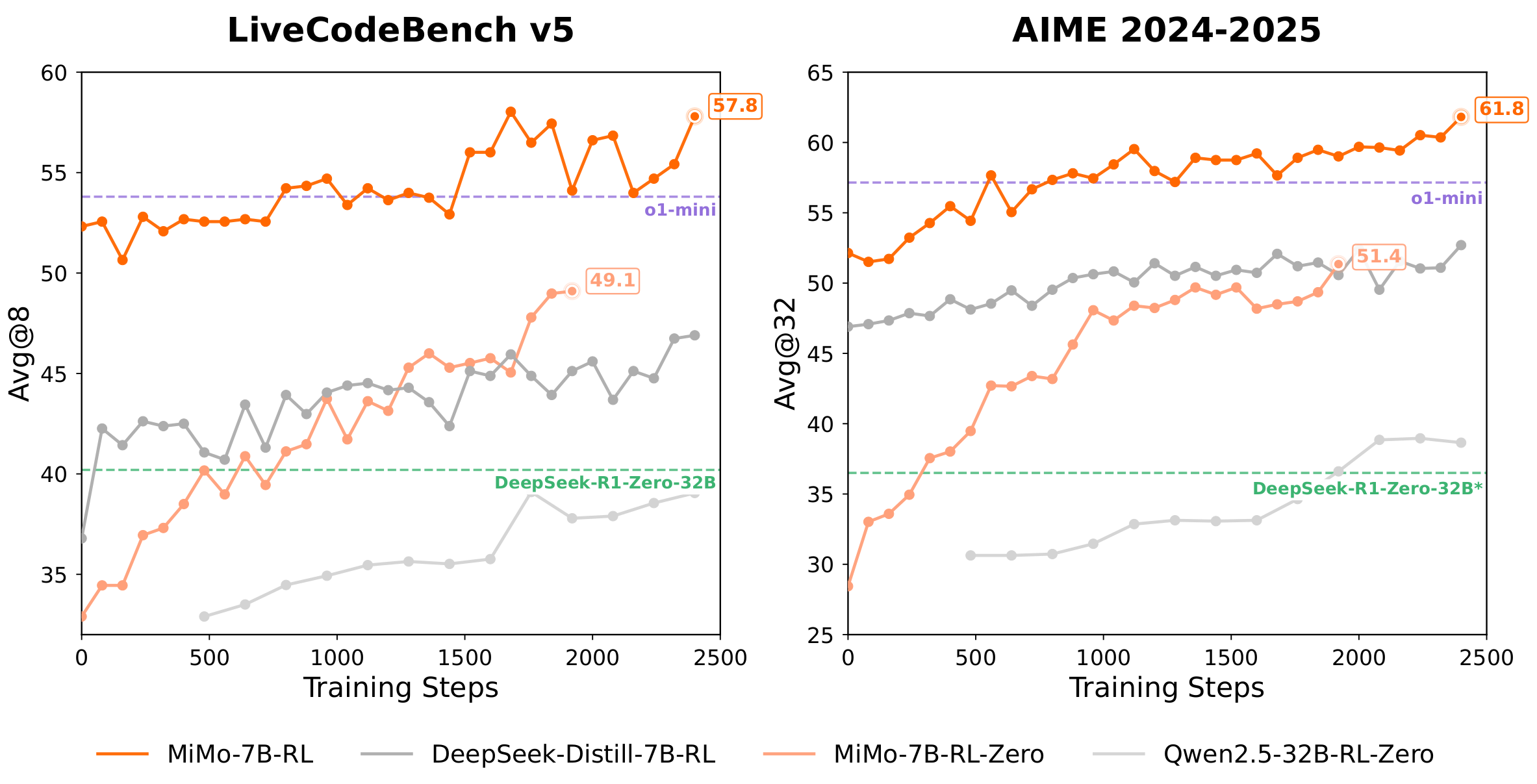
可以看到,在LiveCodeBench v5和AIME 2024-2025上,比同级别的deepseek和qwen2.5-32b-rl-zero都强。
但如果结合昨天qwen3的发布,可能是qwen3-4b的级别。
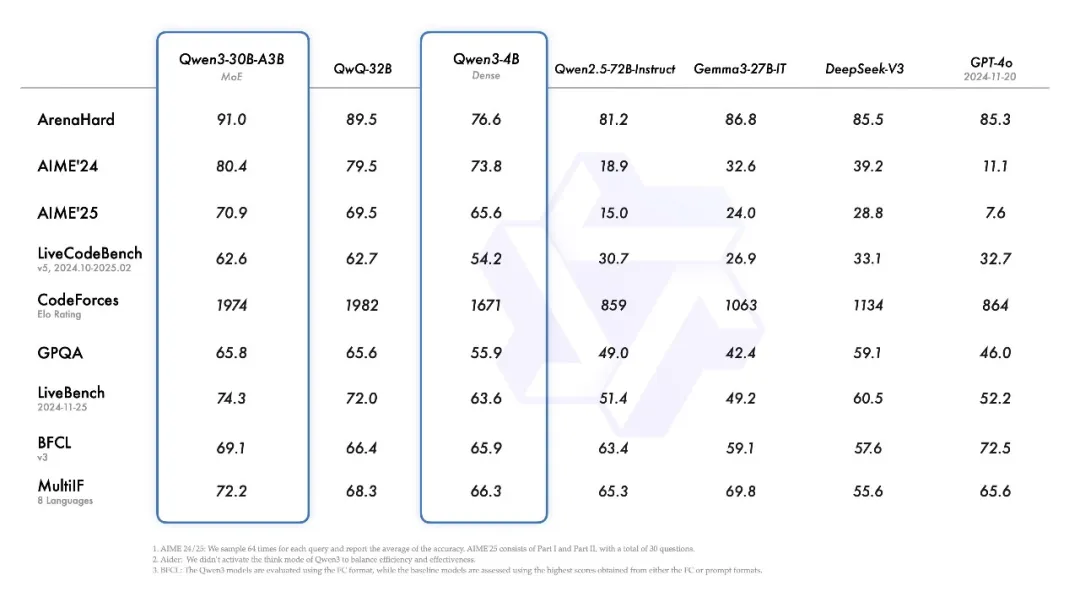 qwen3成绩
qwen3成绩说实话,7B这个量级的模型,还是很难有太强的推理能力的,因此这个量级的模型,偏科其实反而是一件好事,如果能在某个方面达到满血模型的90%能力,但另一个方面只有满血模型20%能力,那也算是能用的垂直领域模型。
不过,这个级别的模型的比较,都是「菜鸡互啄」,7B级别的模型要用来写代码或者解数学题,都不会好用到哪里去。
其实据传去年小米挖了罗福莉(罗福莉是DeepSeek V2的关键开发者之一)后,我还是期待小米能做出DeepSeek或者Qwen级别的大模型的。(据评论区提醒,贡献者名单里没有她名字,可能并未入职)。这个模型也许只是小米大模型团队探索开源社区的一次小实验而已。再等等,应该后面还有发更大的模型的。