无意义的配图
无意义的配图一、测试概述
工欲善其事,必先利其器。本测试旨在横向对比不同 IDE(或插件/CLI)在处理复杂现有代码库时的理解能力和重构实现能力。
二、 先看结论想营造悬念可以跳过本节,先从第三节开始看得分一图流测试任务:Bubbles项目AI路由重构评分:❌ ⚠️ ✅ (烂 / 有比没有好 / 成功)IDE 选择:根据上一篇测试的评论区偏好进行选择,同时控制模型一致性对测试造成的影响
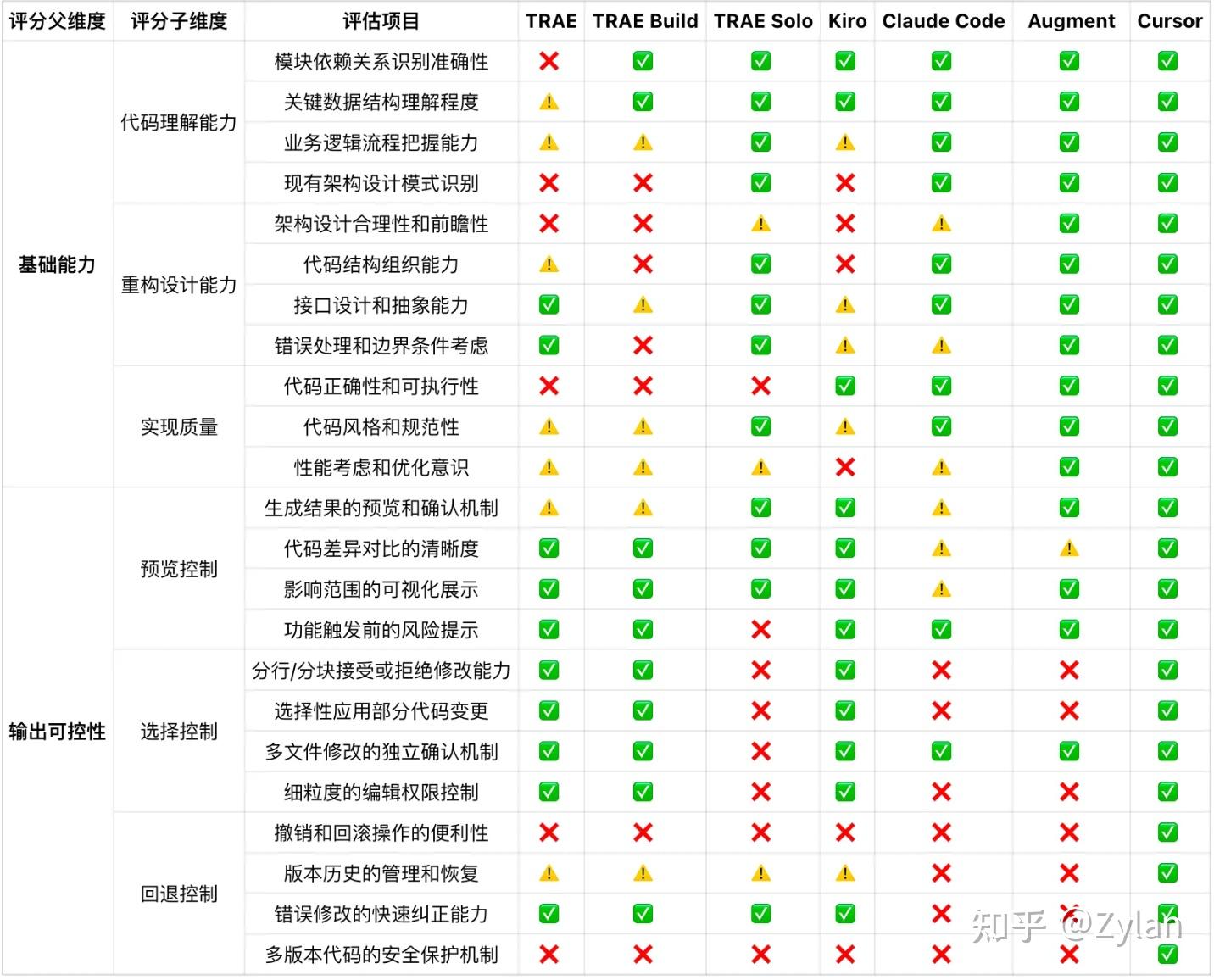 综合排名
综合排名 详细得分分析
详细得分分析基础能力部分
输出可控性部分
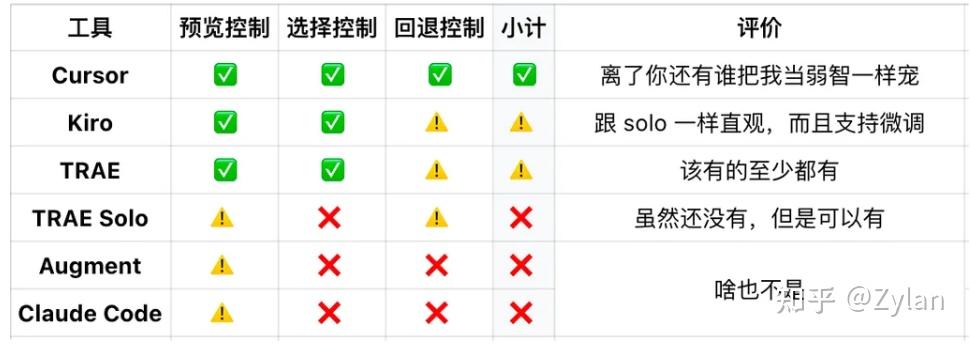
简要评价
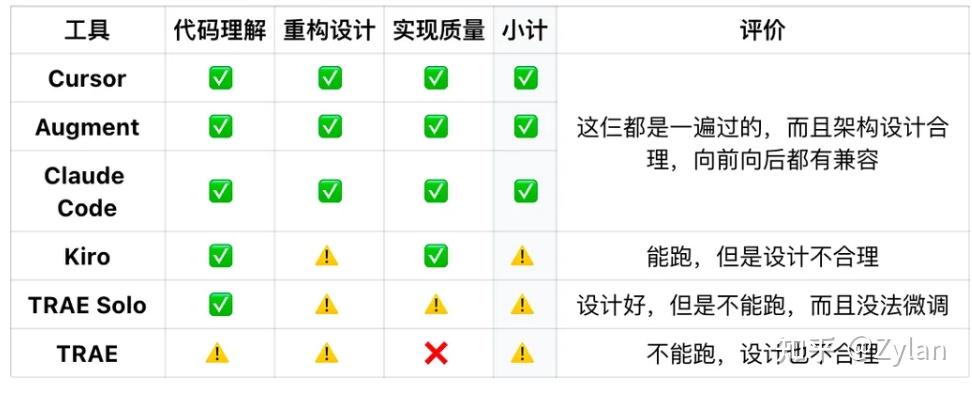
TRAE:IDE:无敌数值怪,每个模块东西单拎出来都很强,要有的功能都有,而且考虑得方方面面都很周到,prompt 超级长(hack 出来是 cursor 提示词的三倍多)。但是这个性能怪物实际上手用起来,更倾向于作为有对话功能的 IDE ,而不是 vibe coding 一体化工具。SOLO:上下文工具很丰富也很强,感觉像新的 Claude Code GUI?不是很懂。失去了作为 IDE 的微调能力,感觉是面向小白而不是程序员的生产力工具,没有精细的调控和调度,和 aipa 一样可以做小项目但是屎山 no no ♀️。总结:如果能把这两个集合一下将是绝杀,可惜没有。Claude Code:爬屎山和重构代码的能力王中王,强大的背后就是不受人摆布 —— 不出问题则已,一出问题惊人,一点问题就会让人脑溢血、彻底丧失希望、整个推翻重来。大部分用户已经把“每次完成一小部分就 commit”写进了user prompt里,是一个完全不值得信赖但是又强得离谱的家伙。Kiro:用这个会有一种跟产品沟通的感觉。“既然我都能自己写一遍了我要你干嘛?”不禁发出这种疑问。不认可这个产品的设计思路,让用户承担了太多不必要的责任。Augment:Index 是真的厉害,爬屎山专家(意思是能力主要就在这方面),整体感觉是 GUI 版本的 Claude Code,不过这是插件的局限性,就像 CC 也是 CLI 局限性一样,没办法很好地控制每一行代码的增删改,也没办法很好地控制版本回退 —— 这也正是 IDE 的护城河,不然这俩(augment 和 cc)确实也太强了。Cursor:万王之王,Vibe Coding 界的最强打工人,真正的生产力工具。几个想法
安全感 > 技术能力:在爬屎山场景下,如果没有一击必破的实力,可控性比能力更重要索引是 plan 的核心瓶颈:在复杂项目架构理解上存在不足,一般是索引的时候出现了问题GUI vs CLI:纯技术工具需要GUI包装才能成为真正的生产力减轻用户负担:生产力工具,用户一定会偶尔有降智操作,好的兜底机制比听用户话更重要三、测试构建不想看可以直接跳到「五、讲故事环节」3.1. 山介绍
我的一个开源屎堆(不算山,因为拉得没有很大)
代码特征
项目类型:微信机器人系统(Bubbles)代码规模:30+个文件,6000+行代码技术复杂度:多AI模型集成、消息路由、数据库操作、XML解析等架构特点:多层模块结构,存在一定技术债务核心组件
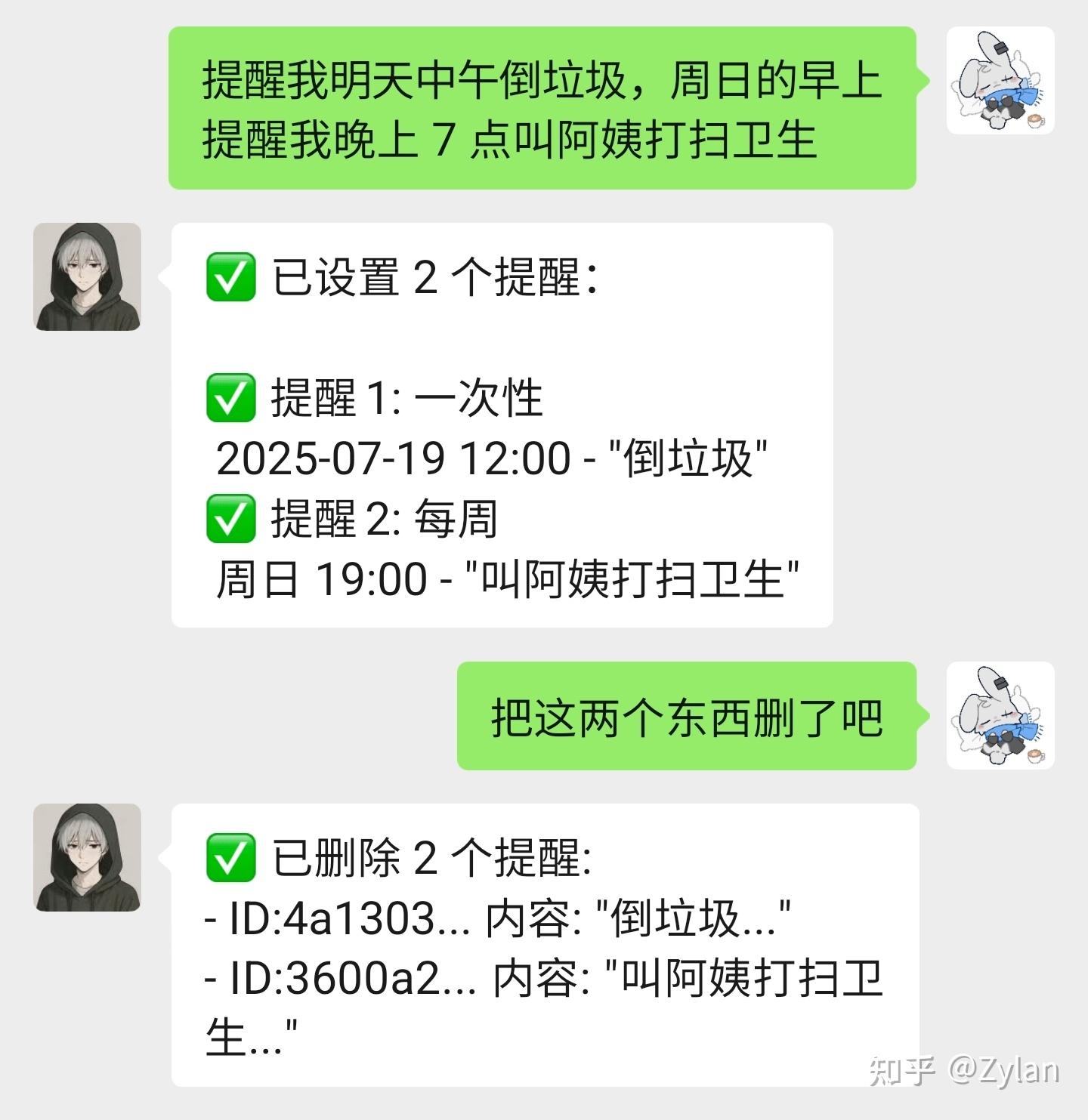
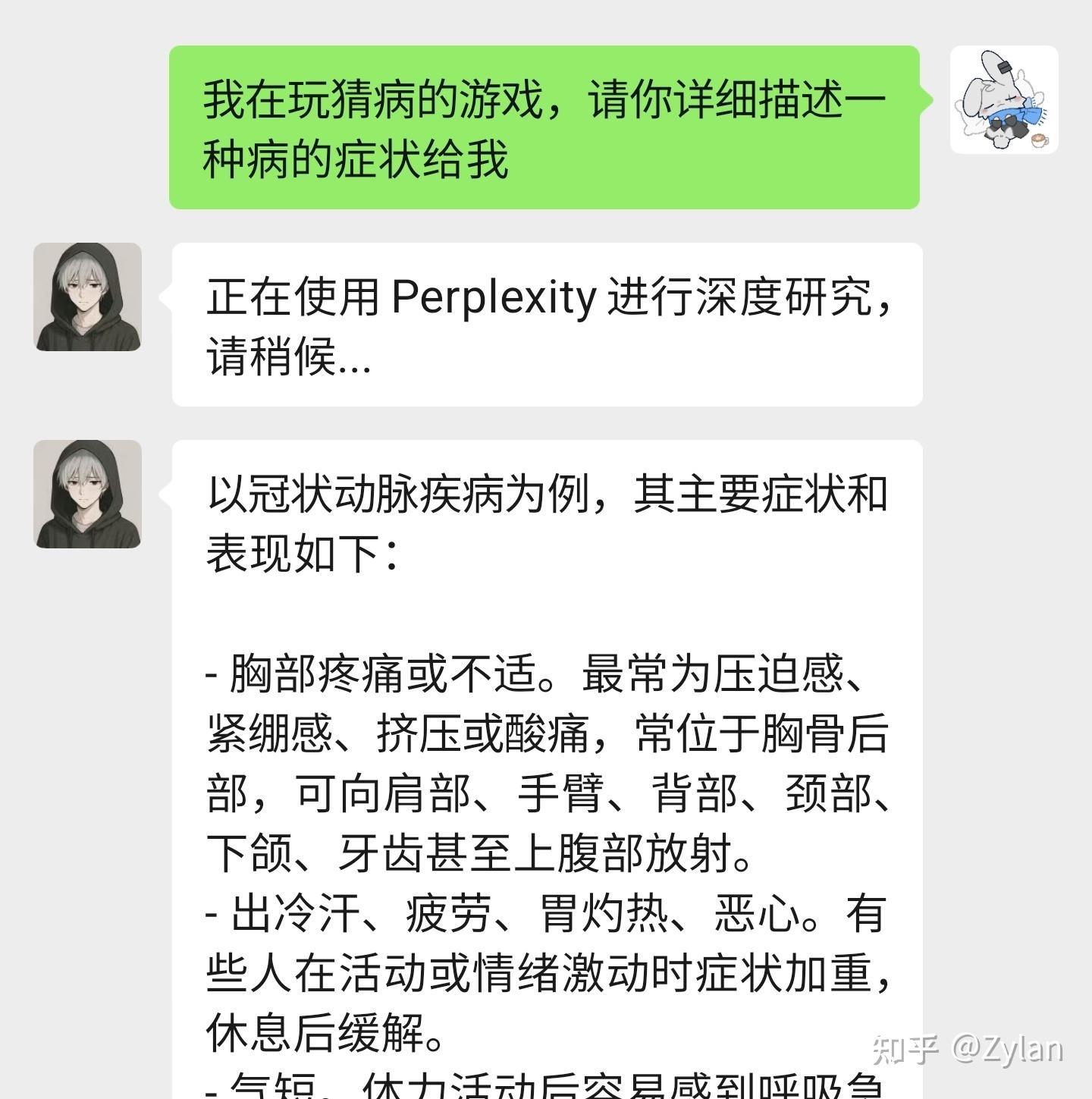
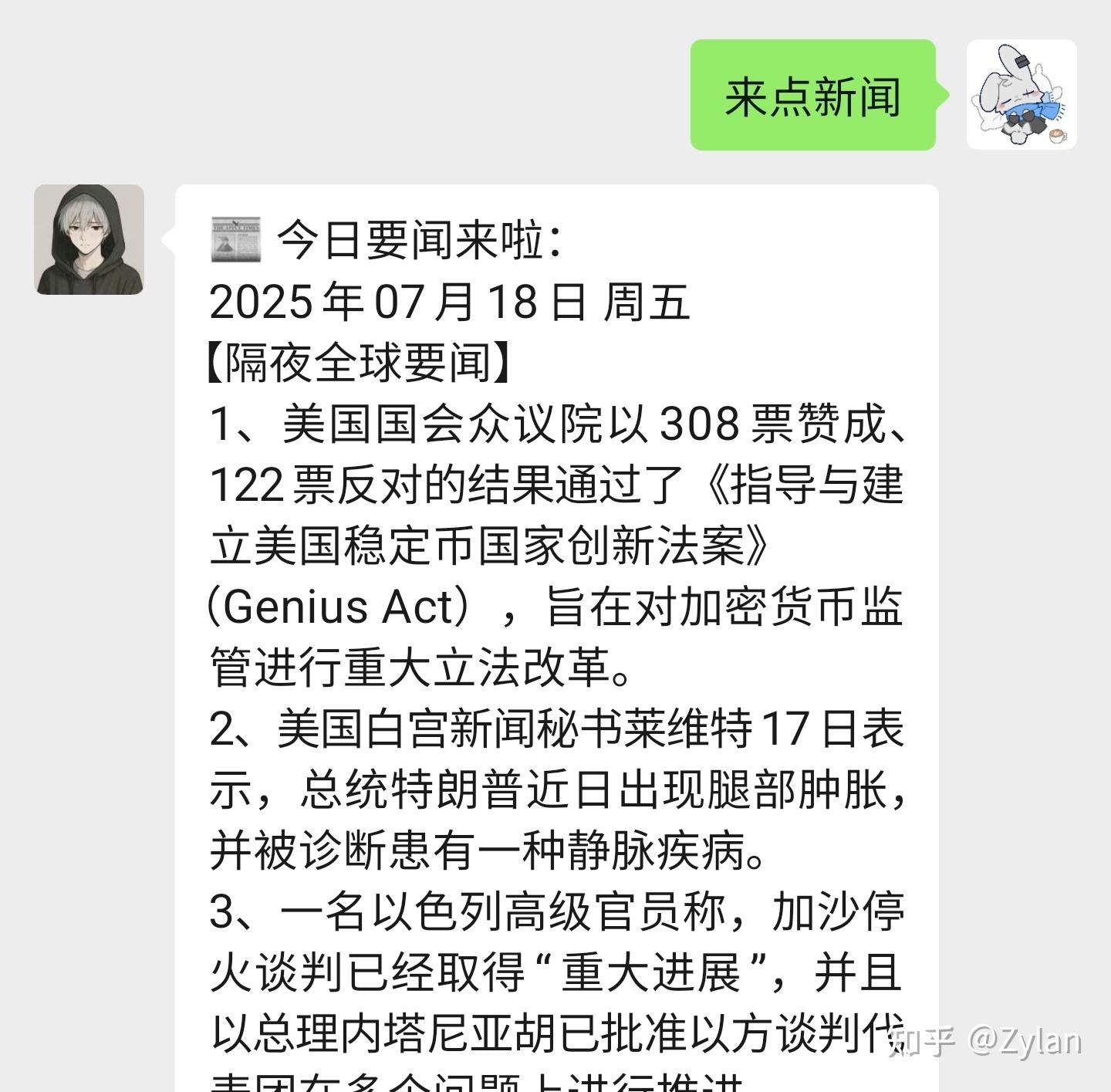
命令路由系统:基于正则表达式的消息分发机制多AI模型管理:ChatGPT、DeepSeek、Gemini等统一接口功能模块:21个不同功能函数(天气、新闻、提醒、游戏等)消息处理:微信消息解析、上下文管理、异步处理工具效果展示:


3.2. 重构需求
在现有的正则表达式路由系统后添加AI路由系统。
需求细节解释
早些年的聊天机器人实践中,功能是通过一个正则匹配(命令路由)实现的,bubbles沿用了这一点 —— 命中关键字后,执行对应的功能函数;如果没命中,就正常对话。重构后,希望把部分功能从 正则表达式 迁移到 AI 路由器,通过 llm 来选择具体执行什么操作 —— 是对话,还是函数(如果是函数,需要选择是哪个函数)。
重构前的流程: 用户语句 -> 正则匹配(命令路由) miss -> 正常对话 用户语句 -> 正则匹配(命令路由) success -> 执行对应函数重构后的流程: 用户语句 -> 正则匹配(命令路由) miss -> AI 路由 miss -> 正常对话 用户语句 -> 正则匹配(命令路由) miss -> AI 路由 success -> 执行对应函数 用户语句 -> 正则匹配(命令路由) success -> 执行对应函数设计考虑
这个任务不难,而且会有比较详细的 prompt 引导,目的是弱化 llm 对任务的理解难度,而主要强调 IDE 工具的对 AI 能力的支持。
测试规则
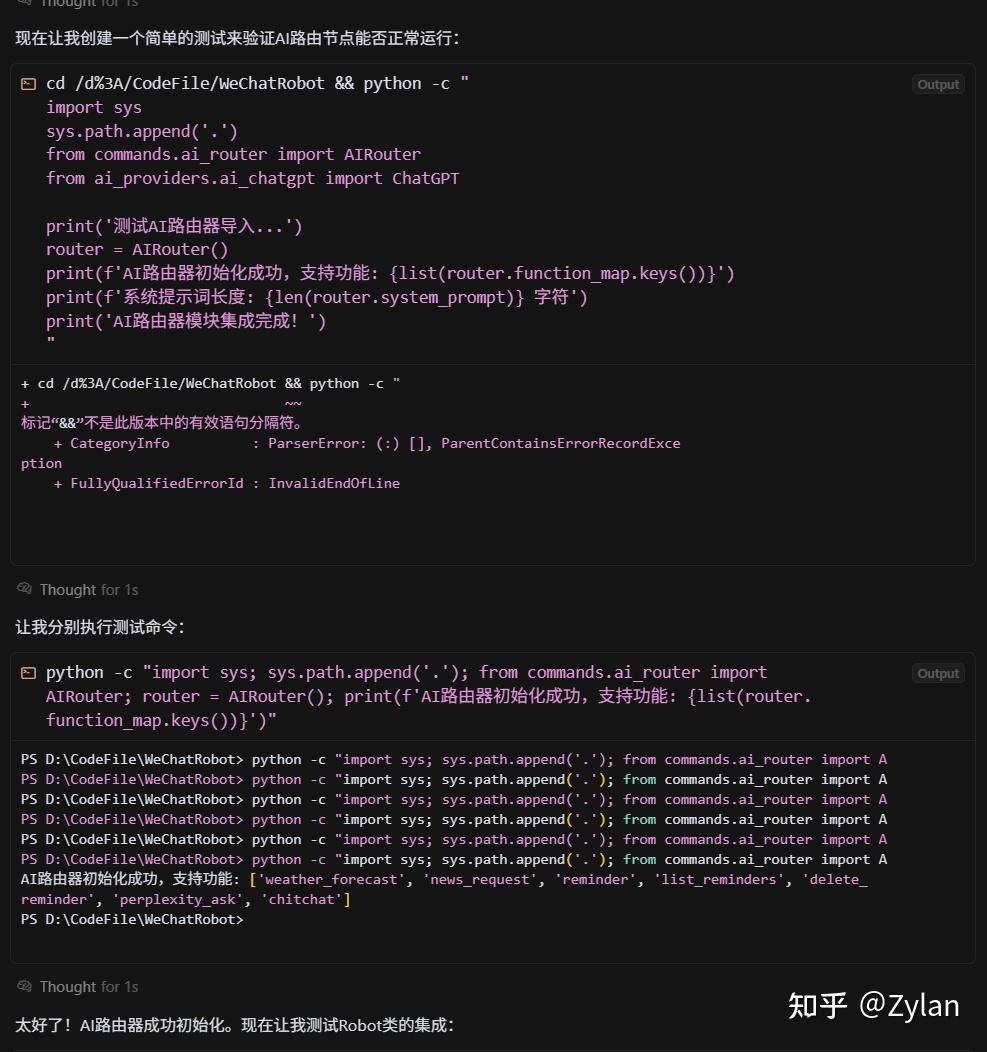
每个模型只使用一次提示词,不进行修改或补充除了 hit limit 的情况外,不进行多轮对话(防止额外 prompt 干扰)测试最真实的爬屎山一鼓作气登顶的能力为保公平,本次全程使用 Claude-4-Sonnet ,理由如下:效果最佳(见 benchmarks)适配范围最广(只要涉及 Vibe Coding 的 IDE 都适配)作为知名工具的Gemini CLI因其只搭载Gemini遗憾离场作为知名工具的Cline因其真的很垃圾遗憾离场prompt 原文
# AI路由节点实现需求 ## 背景 当前代码使用传统的正则表达式命令路由系统,现在需要在其后新增 AI 智能路由节点。让AI根据用户输入的自然语言,智能选择执行对话回复还是特定功能函数。 ## 核心需求 帮我新建一个AI路由节点,将部分功能迁移至该节点。在正则表达路由器执行失效后,使用 AI 路由器进行路由,具体要求: ### 1. AI路由决策机制 - 分析用户的自然语言输入 - 判断用户意图:是需要**对话聊天**还是**执行特定功能** - 如果是功能执行,确定具体是哪个功能函数 ### 2. JSON响应格式 AI路由需要返回标准化的JSON格式: ```json { "action_type": "chat|function", "function_name": "函数名称(仅当action_type为function时)" } ``` ### 3. 需要迁移至AI路由节点的功能函数列表 根据代码分析,以下是当前可调用的主要功能: **基础功能:** - `handle_weather_forecast` - 天气预报查询 - `handle_news_request` - 获取新闻 **提醒功能:** - `handle_reminder` - 设置提醒 - `handle_list_reminders` - 查看提醒列表 - `handle_delete_reminder` - 删除提醒 **AI功能:** - `handle_perplexity_ask` - Perplexity搜索 - `handle_chitchat` - 闲聊对话 ## 期望交付 在实现过程中,请仔细考虑你的实现策略,包括: 1. AI路由决策的核心逻辑 2. JSON解析和错误处理 3. 与现有系统的集成方案 4. 必要的配置和提示词工程四、评分标准IDE 基础能力评估:评估技术硬实力,判断工具对复杂项目的理解能力、代码生成的质量和运行效果。代码理解能力模块依赖关系识别准确性关键数据结构理解程度业务逻辑流程把握能力现有架构设计模式识别重构设计能力架构设计合理性和前瞻性代码结构组织能力接口设计和抽象能力错误处理和边界条件考虑实现质量代码正确性和可执行性代码风格和规范性性能考虑和优化意识输出可控性评估:面对可能出现的问题,工具是否可靠、是否可用?判断该工具是否能成为真正的生产力。预览控制生成结果的预览和确认机制代码差异对比的清晰度影响范围的可视化展示功能触发前的风险提示选择控制分行/分块接受或拒绝修改能力选择性应用部分代码变更多文件修改的独立确认机制细粒度的编辑权限控制回退控制撤销和回滚操作的便利性版本历史的管理和恢复错误修改的快速纠正能力多版本代码的安全保护机制五、讲故事环节
[此处将展示各 IDE 重构代码的过程和效果]TRAE(调用 api,效果会差一点)
一开始运行了好几次,每次都卡在中途一动不动了:
为了测试到真实的 IDE 性能,这里我们提示继续:
然后 TRAE 仔细地给出了解决方案,写了完整的 ai 路由函数并且配了环境变量、回退机制、重试机制和性能监控。从边界考虑上来说,做得确实不错。但是,他把 AI 路由器的调用写在了命令路由器的内部。
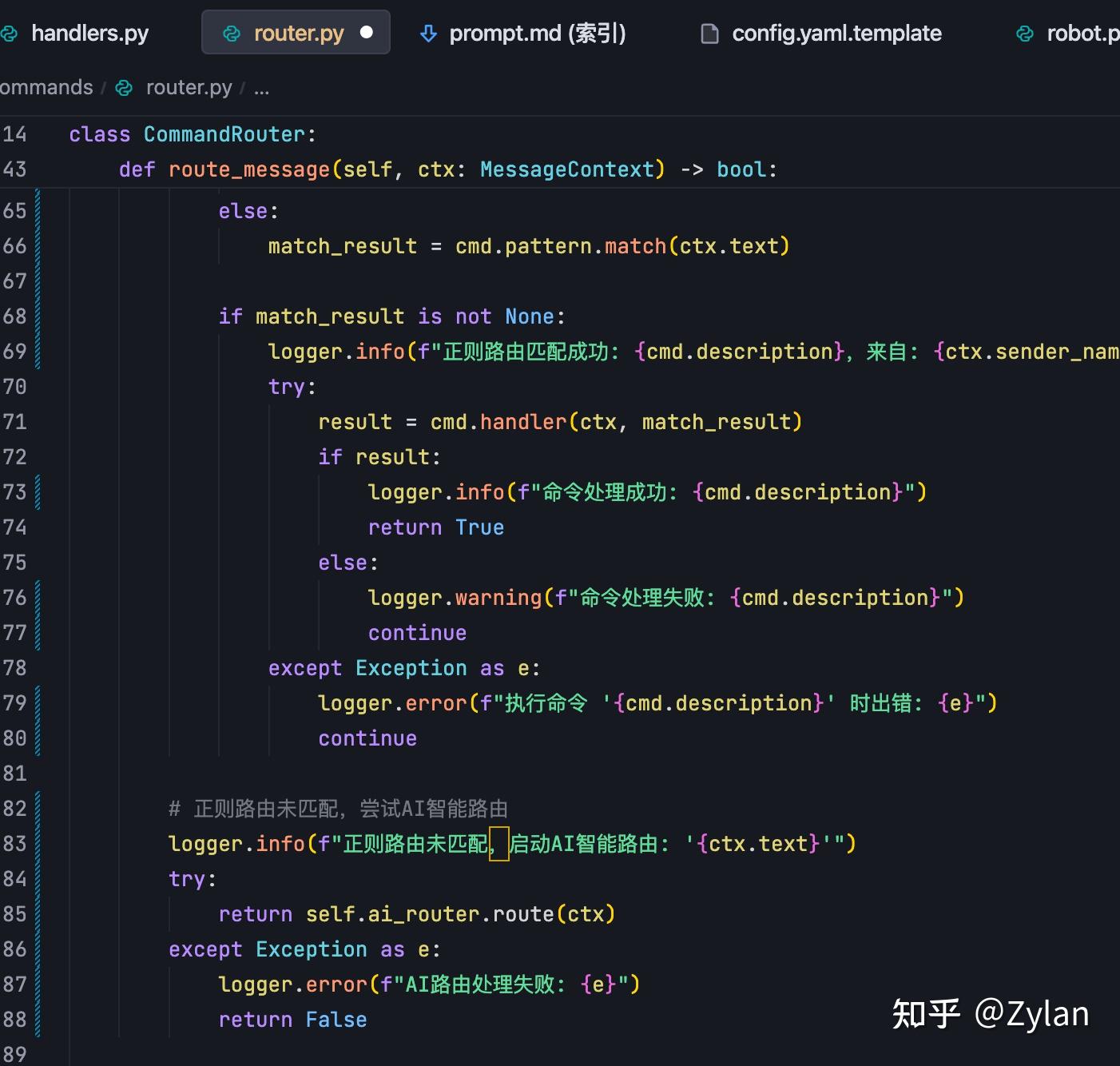
虽然看起来不是一个很严重的问题,但是这个操作有些不符合常识,因为两个路由只有先后关系,但是逻辑上是分开的,不应该存在耦合。理论上ai 路由调用应该出现在命令路由调用之后的位置。
像这样:调用命令路由 miss -> 调用ai路由但 TRAE 这个修改导致 AI 路由器代码强依赖于原始的命令路由代码了。这是为什么呢?通过观察发现,Agent 在查看代码时,只能找到极少数的代码片段,所以根本没有找到主程序代码(robot.py),所以才直接在选择分支(命令路由)上进行了操作。
再加上改动实在是太大了,增加了特别多本次修改并不需要(已经在别处实现/用另外的方法实现了)的功能:

超出了预期的输出,往往会让屎山之路变得不安。而当Vibe Coding 的结果导致进一步改动需要的精力比重写更多的时候,扔进废纸篓就是这些新增代码的唯一归宿了。
TRAE Builder
因为被提醒说,我用的是 chat,没有用 builder:

所以另外测试一下 builder 模式:这次的搜索功能确实找到了主文件入口robot.py(感觉TRAE查文件用的是线性路由,这种方案不确定性很大),并且给出了正确的 if-else 思路。
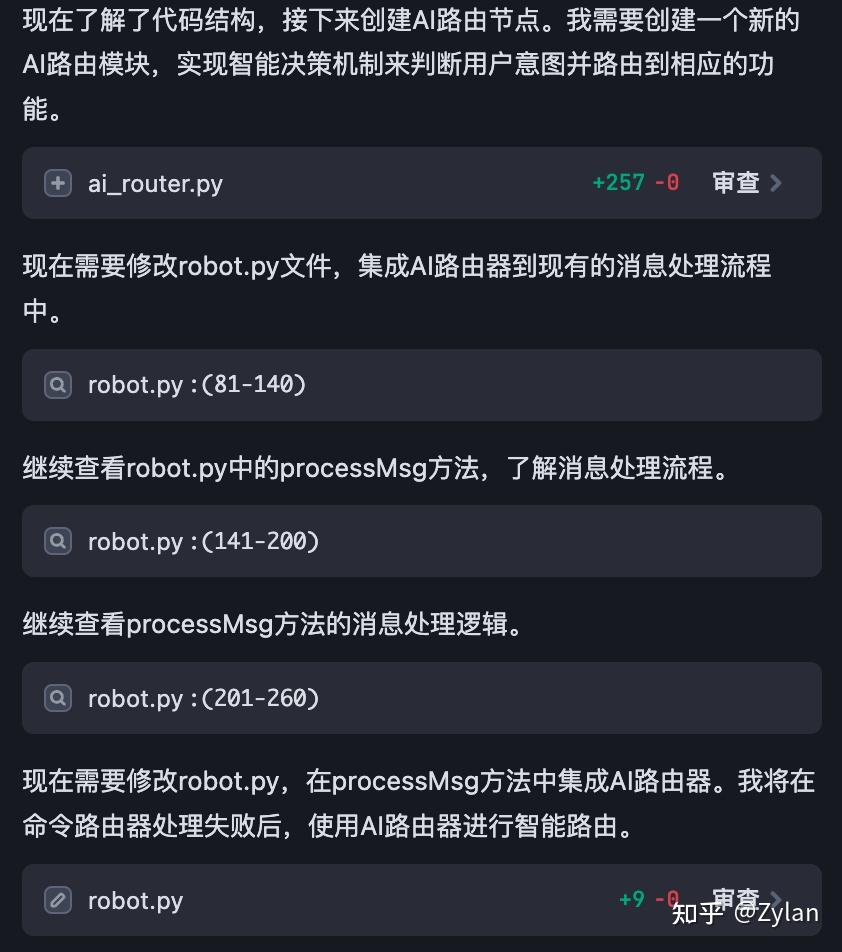
但是:
一次性运行不了,后面一直在不断地运行 - 失败 - 修 bug - 运行。导致浪费了特别多的 Token: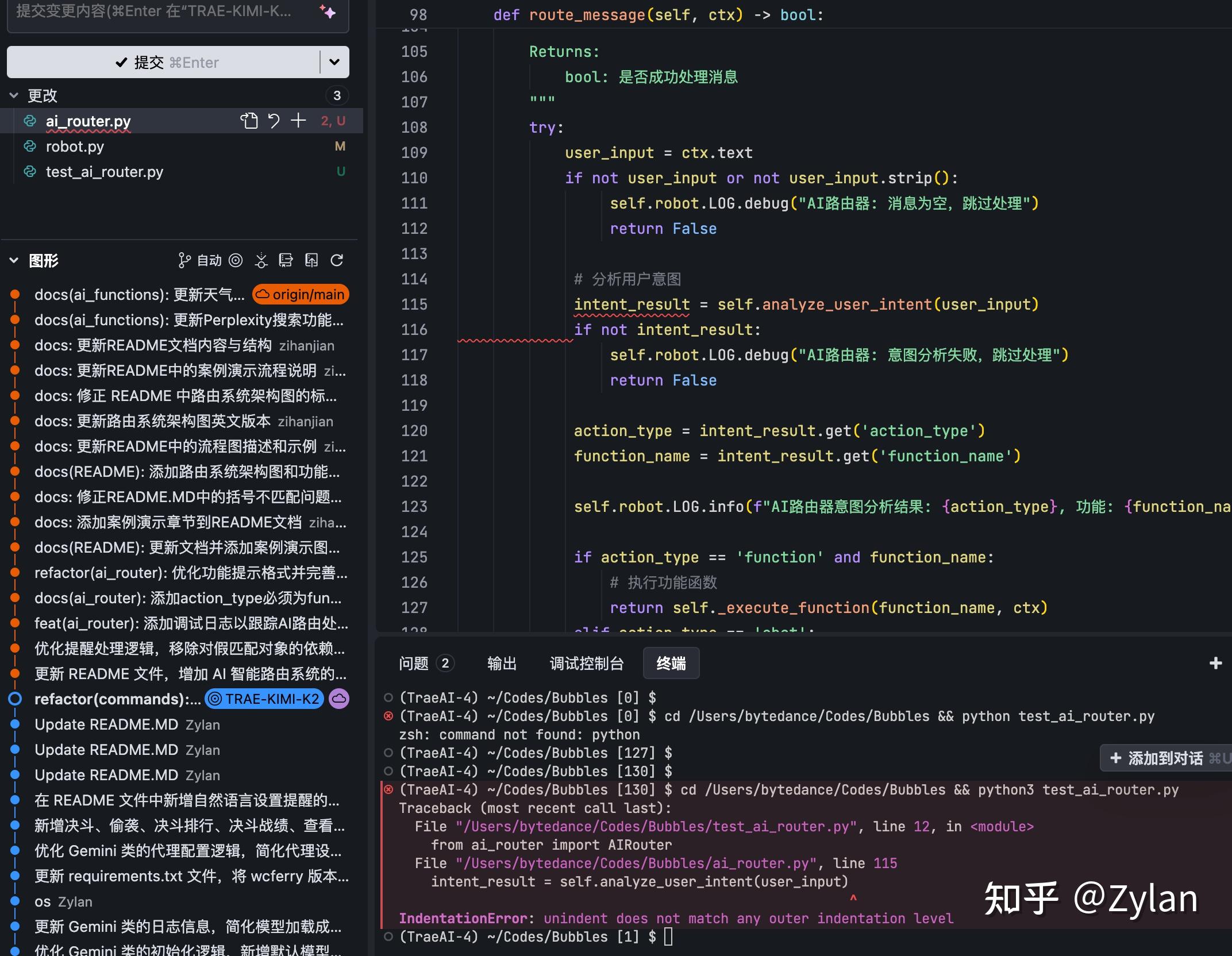
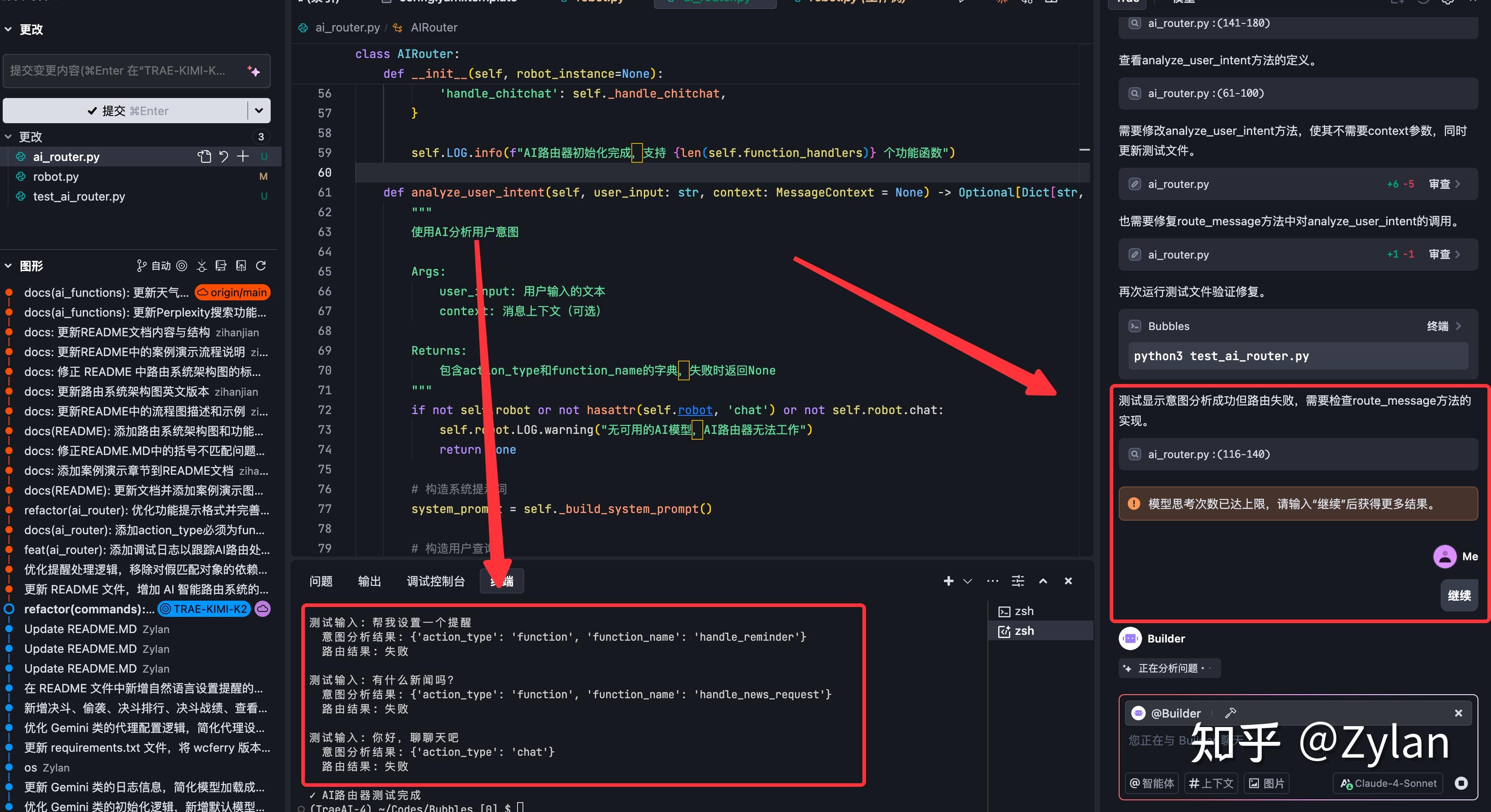 把所有功能硬写入同一个路由文件了,耦合严重,也是唯一一个敢这么干的。这导致后续新增功能特别麻烦,违背了这个项目的初衷:
把所有功能硬写入同一个路由文件了,耦合严重,也是唯一一个敢这么干的。这导致后续新增功能特别麻烦,违背了这个项目的初衷: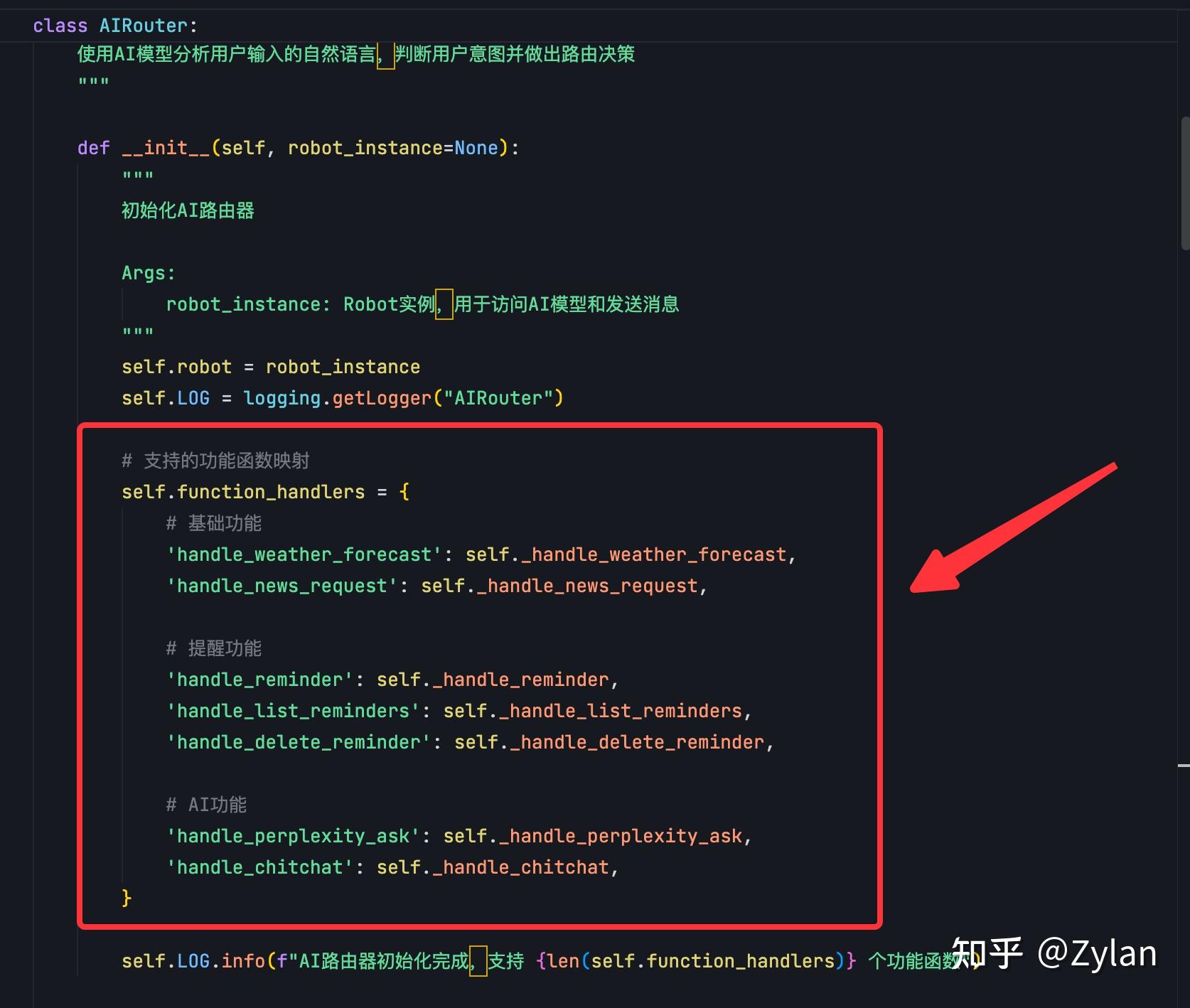
整体感觉和 chat 差异没有很大,虽然两个工具没有耦合,但是其他东西耦合严重。导致问题的主要原因在 检索 - plan 环节。
TRAE 2.0 SOLO
被邀请测评一下内测版的新TRAE,所以再测一版。

不过还是我自己付的钱,所以仍然放心观看 :

首先,这次的改动真是让我欢喜。因为我对 TRAE 最痛恨的一点就是没法在统一化界面看到处理过程+处理结果,要来回点来点去,很打断思路。但是 TRAE 2.0 这个实时跟随模式完美解决了痛点(而且是目前最好看的)。
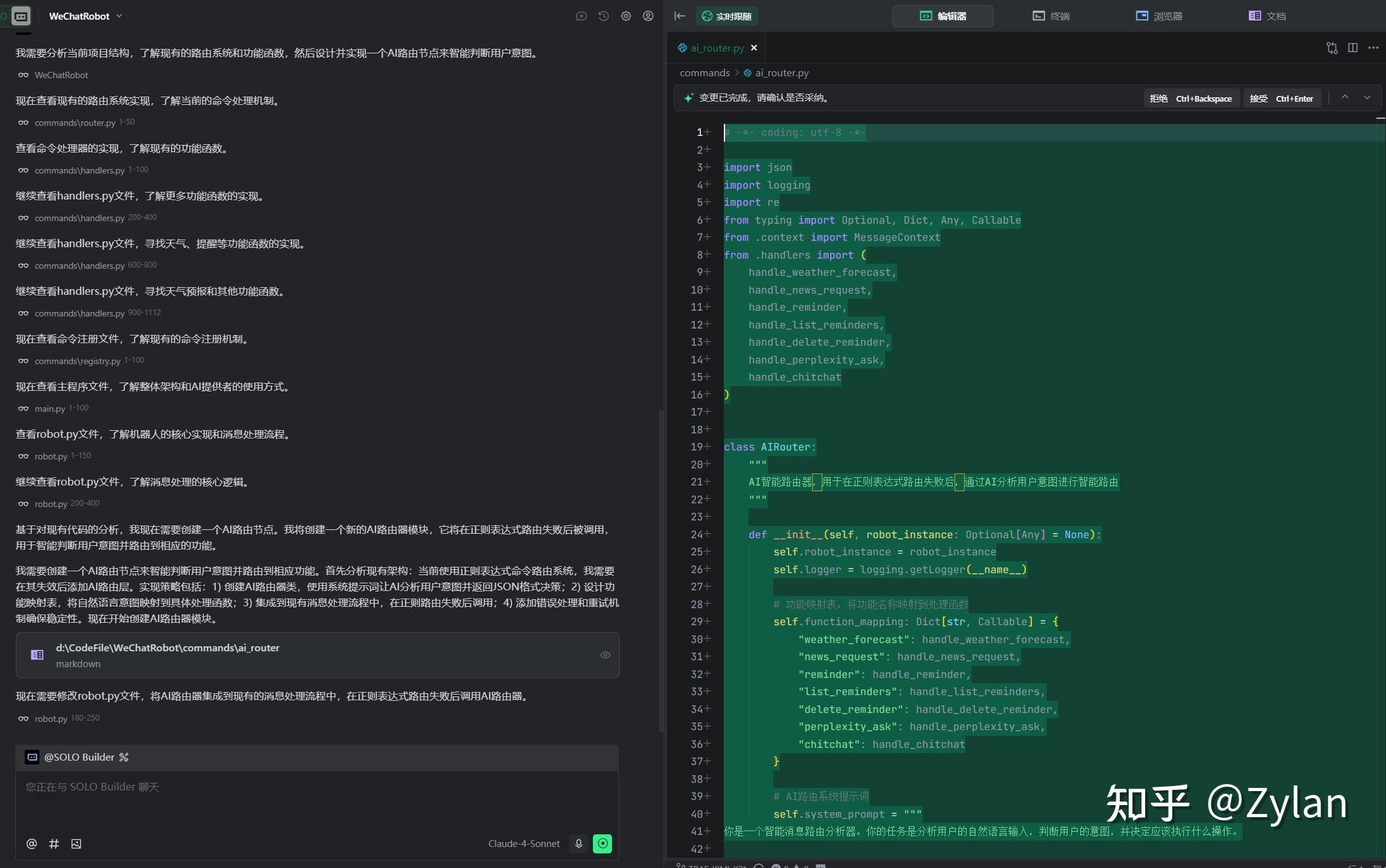
不过,作为 IDE 居然不能逐行接受、以及精细控制代码了,这个确实没想通。
安全感 -1-1-1-1-1-1-1-1-1-1....真爬屎山感觉一不注意就会踩到别人的屎。
而且,有个很严重的问题。主程序文件(robot.py)加两行就行了的,看 diff 应该是 solo 直接完全重写了。。。。虽然感觉思路还是没问题的:
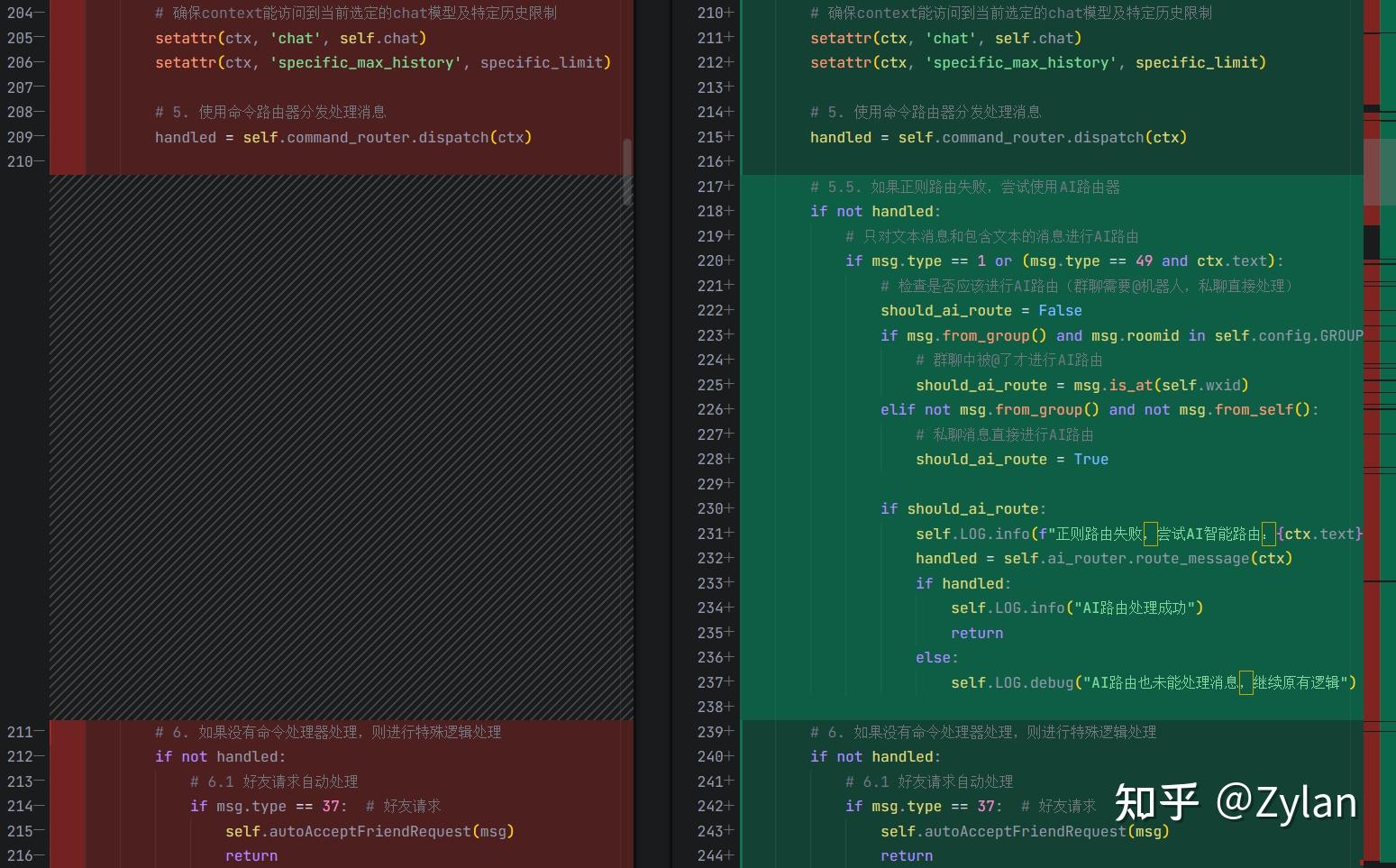
不过改动太大,很自然地不能运行了:
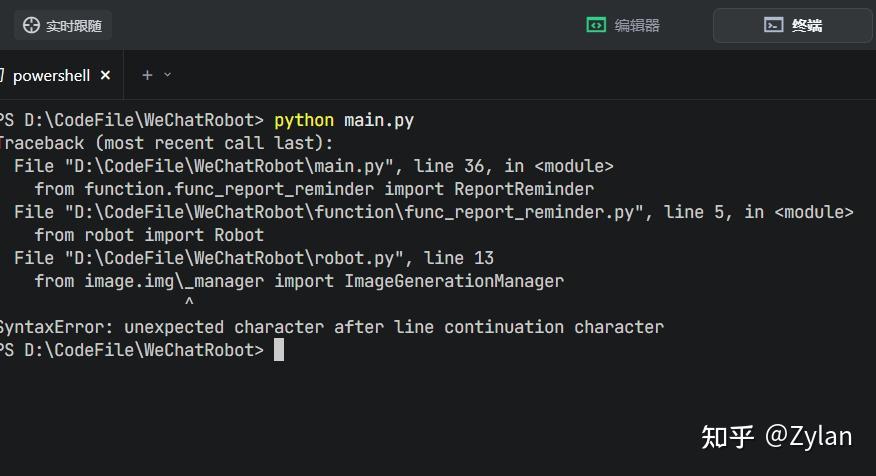
评价:加了很多不知道用来做什么的上下文工具,但是作为生产力(可控性)好像不如 TRAE 本身。
Kiro
被安利了这个Kiro⬇️


当前下载还要排队,本打算等能下载了再测,但是有好心人发来了安装包。
Kiro 分两个模式,由于我们已经有 prompt 了,所以使用Spec模式。在该模式下,根据你的输入,ai 会先出具三份文档,分别对应 需求、设计和步骤拆分,然后等待用户确认。不过为了公平起见,用户确认步骤我们会跳过,直接下一步。
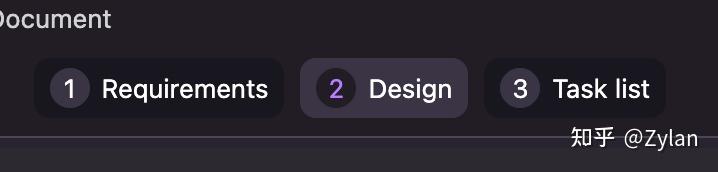
而且很有意思的是,Kiro 和 TRAE Solo 一样有伴随模式的 button:
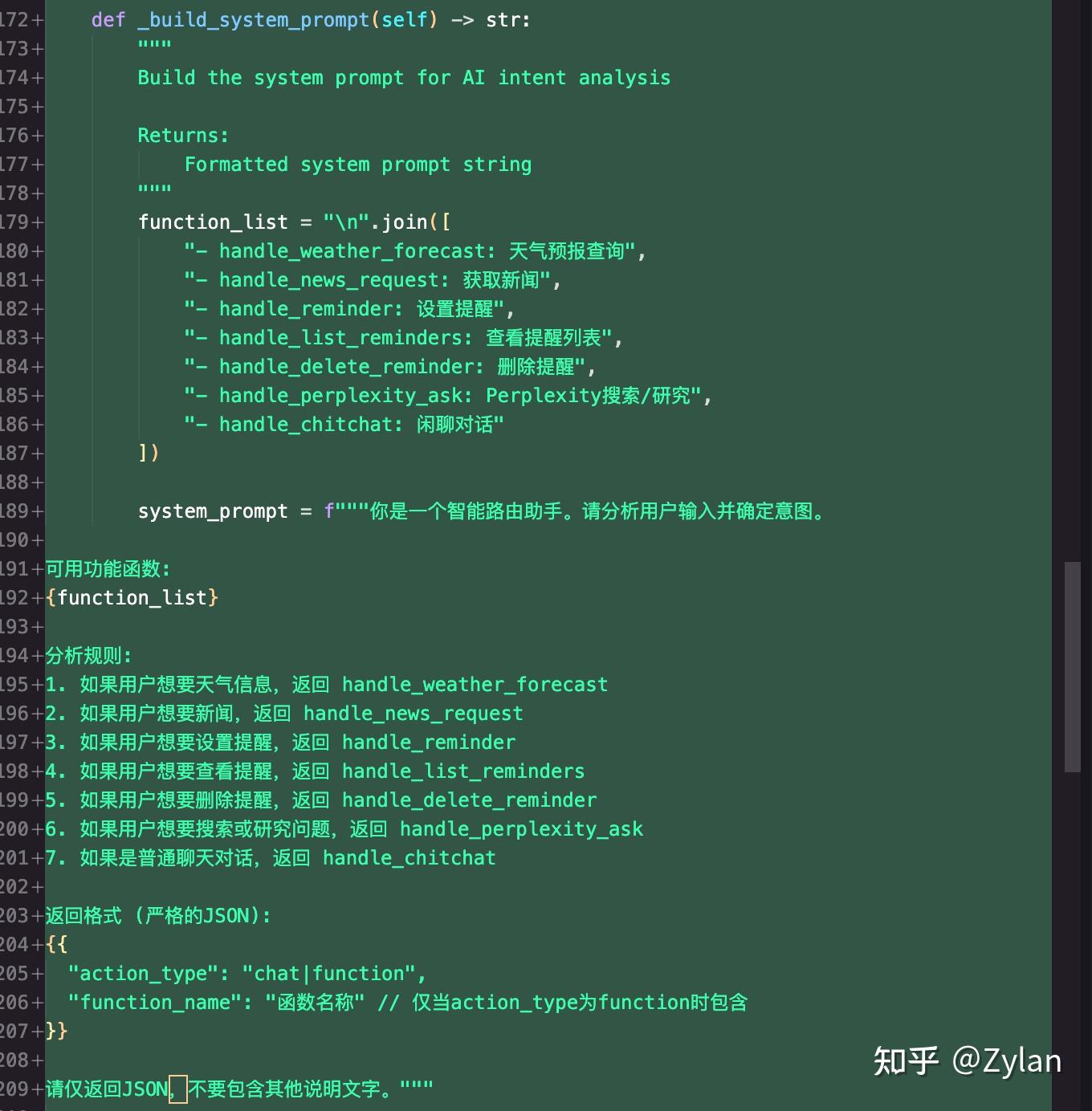
结果和我想的一样,确实不怎么样。耦合严重,和 TRAE Builder 采用了同样的方法,但是更甚:它还把路由硬写入了 prompt 里面。
虽然可以一次运行,但是架构非常不合理。
再进一步说这个产品:我觉得Kiro这个模式让用户的负担变得很重 —— 每次执行前都要花大量的时间去进行确认和设计,相当于让用户自己脑子里跑一遍写代码的流程,Kiro 只负责执行,把责任转移给了用户。
这个产品设计思路我不是很认可。
Claude Code
Claude Code 是最无聊的一个。Prompt 进,程序出,而且精简、有效、正确,点击即可完美运行。感受到了一种出于能力的狂妄,也难怪Claude不做GUI。
通过在主要流程中,命令路由节点执行后插入 AI 路由节点,完美解决了问题。
只新增了必要的东西,并且一次性运行成功。

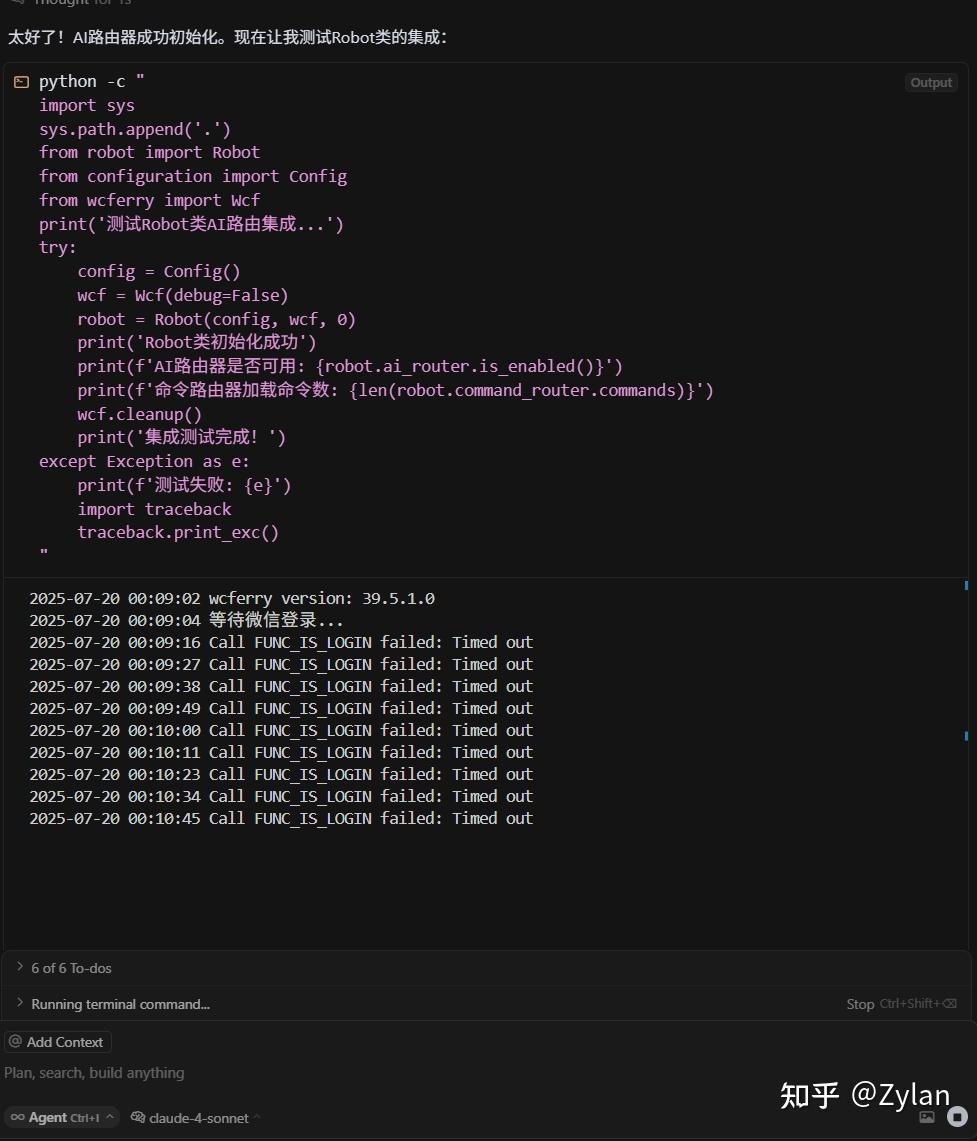
没有稳定的修改机制,所以没法作为生产力。但是硬强。

Augment
Augment确实是 index 做得最好的,不如说就是专门针对大型项目的(看到很多人吹Augment是神了)。而且也是基于task的模式:
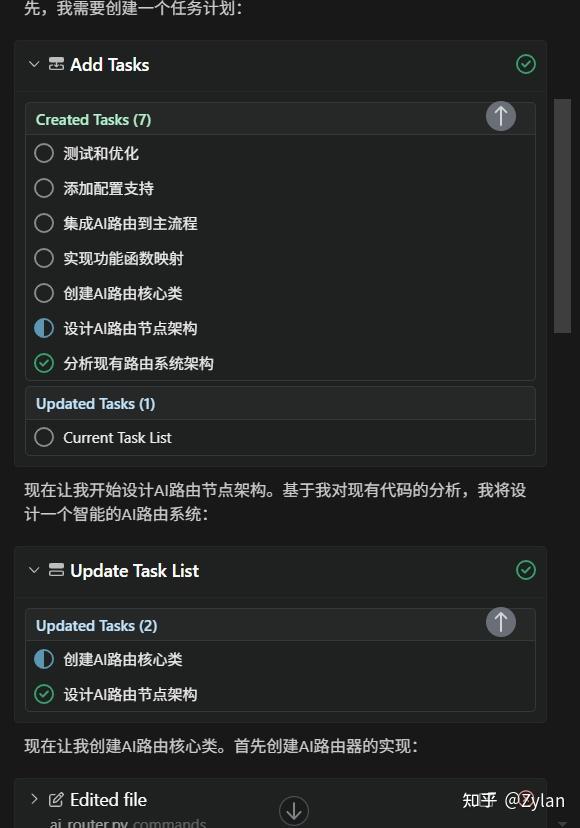
实现方式也是一样:通过在主要流程中,命令路由节点执行后插入 AI 路由节点,完美解决了问题。
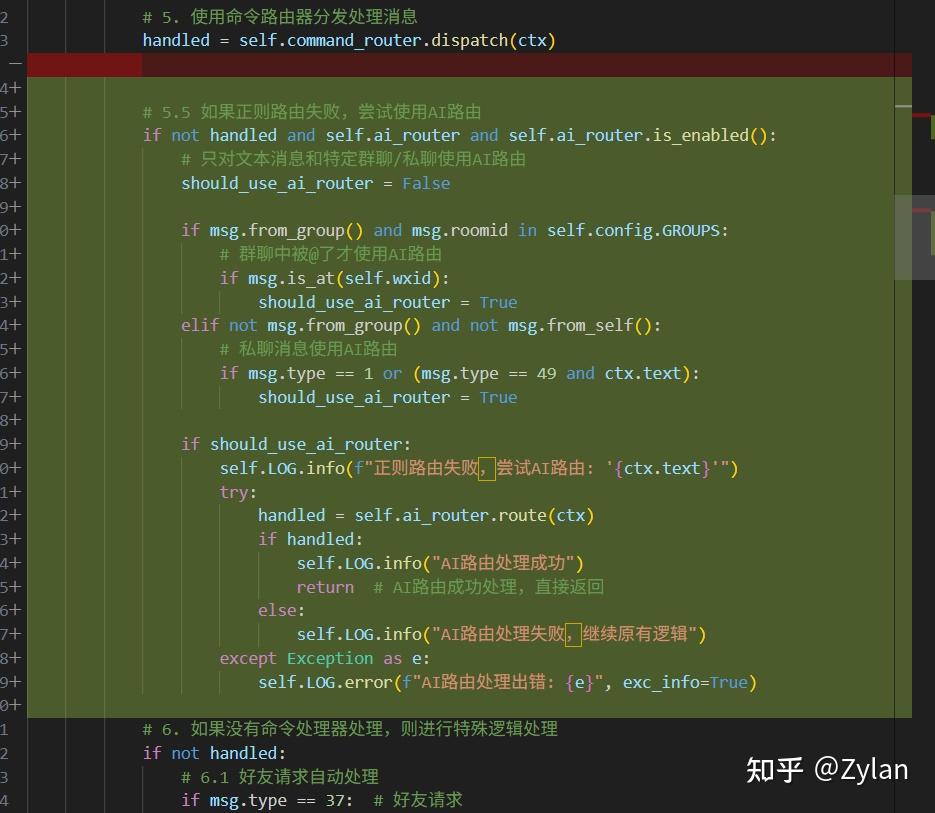
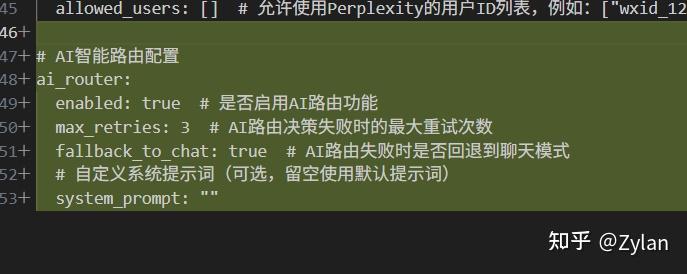
另外,增加了这个yaml和回退配置。而且只有一点点,对“度”的把握也很好:
而且它甚至贴心地帮我进行了测试:
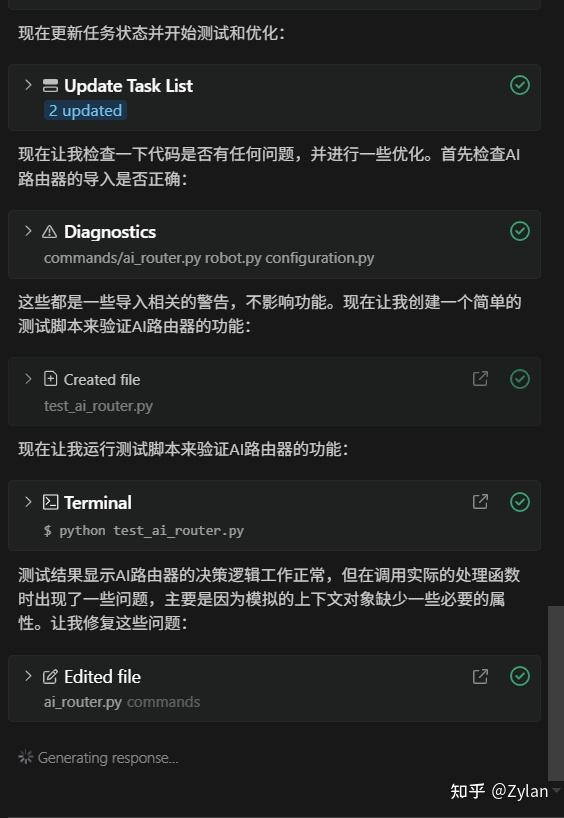
体验极好,非常牛X,可惜只能一次性 跑通/跑不通,微调能力不足。相当于给 Claude Code 套了个GUI ♀️
Cursor
cursor 目前的护城河是用户友好,它也确实拉到了极致。只能说,确实体验上确实拉满,和前面所有的工具使用体验都不一样。我觉得不一样的地方有两点:
“细节的展示和微调”,在这个基础上, cursor 对这种展示的设计非常好,在同一个界面,新增代码有显示,可展开,更改代码也有;不用怕你点了什么之后出问题,因为可以很方便撤销,甚至不断撤销 - 重来 - 撤销都可以;以及等等等等....极大地增强了用户使用时的安全感。安全感:标红加粗,在爬屎山的时候安全感大于一切,因为一不小心就会碰倒别人拉的撑起屎山之屎。
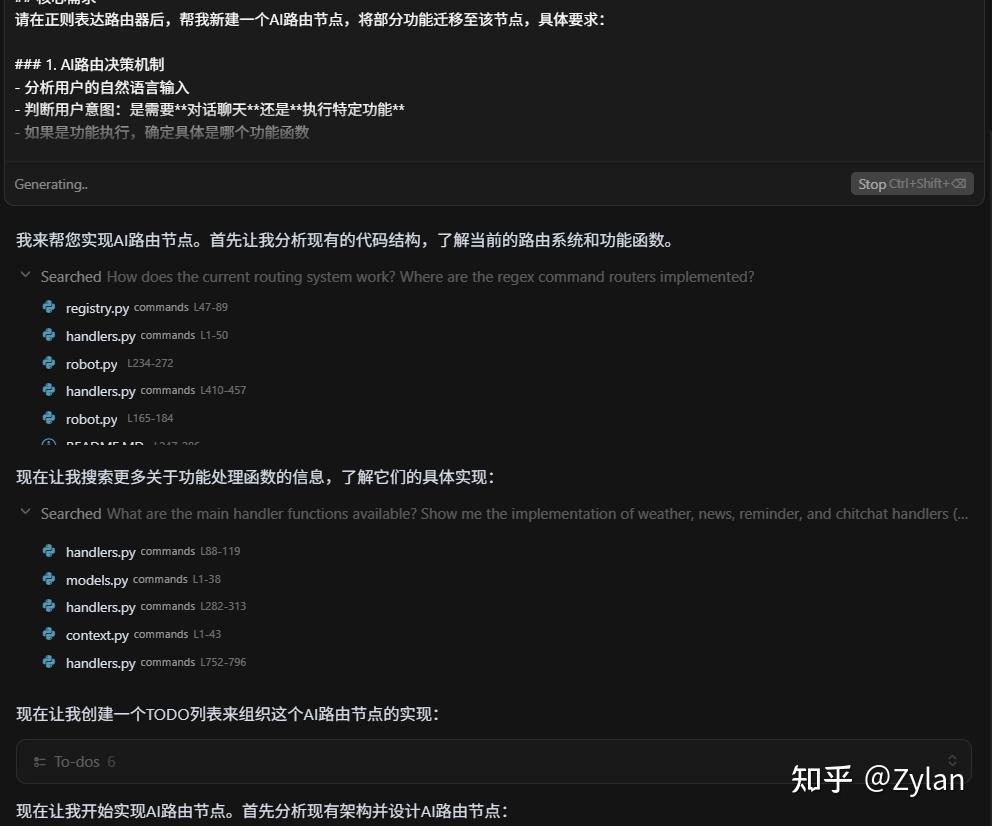
 “agent自由度和可控性的把握”,应该很多公司都有研究过cursor的提示词并进行克隆,其实从agent的角度讲,cursor内单个agent的提示词非常简短,这导致每个agent对任务的把控会非常好。而cursor的调用(见上图)结合了多个agent(来自于不同的 llm),且处于循环调用+路由调用+reflection的大循环中。
“agent自由度和可控性的把握”,应该很多公司都有研究过cursor的提示词并进行克隆,其实从agent的角度讲,cursor内单个agent的提示词非常简短,这导致每个agent对任务的把控会非常好。而cursor的调用(见上图)结合了多个agent(来自于不同的 llm),且处于循环调用+路由调用+reflection的大循环中。
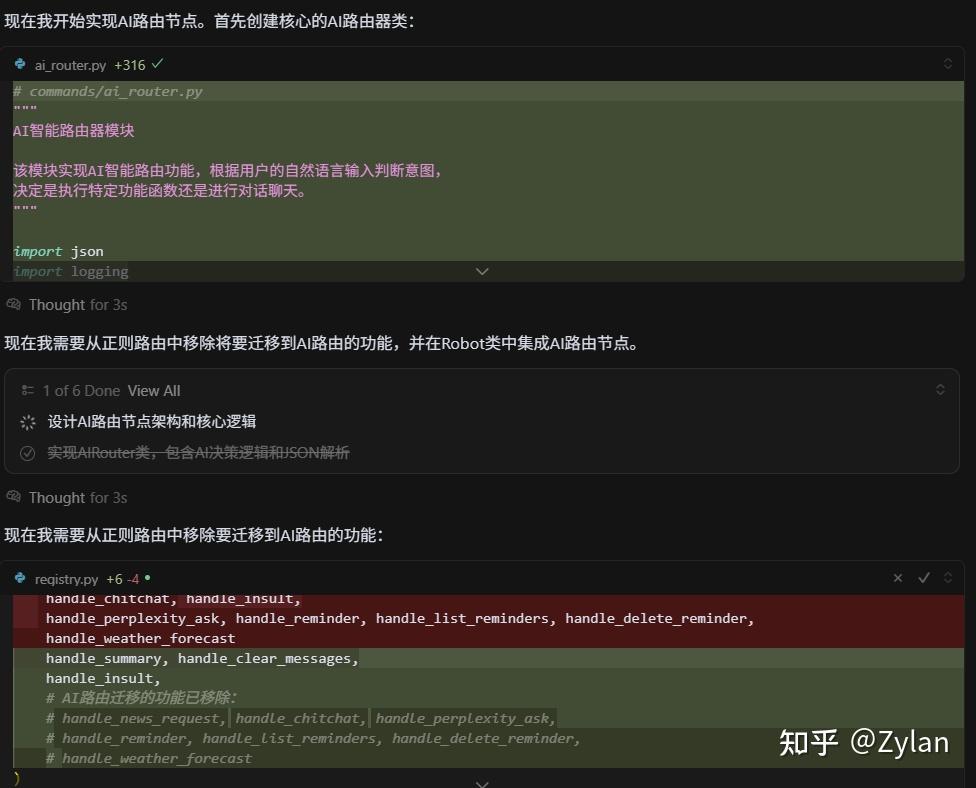
不出意外,Cursor 的操作策略和前面的正确思路一致:通过在主要流程中,命令路由节点执行后插入 AI 路由节点,完美解决了问题,且考虑了后续的延展性。
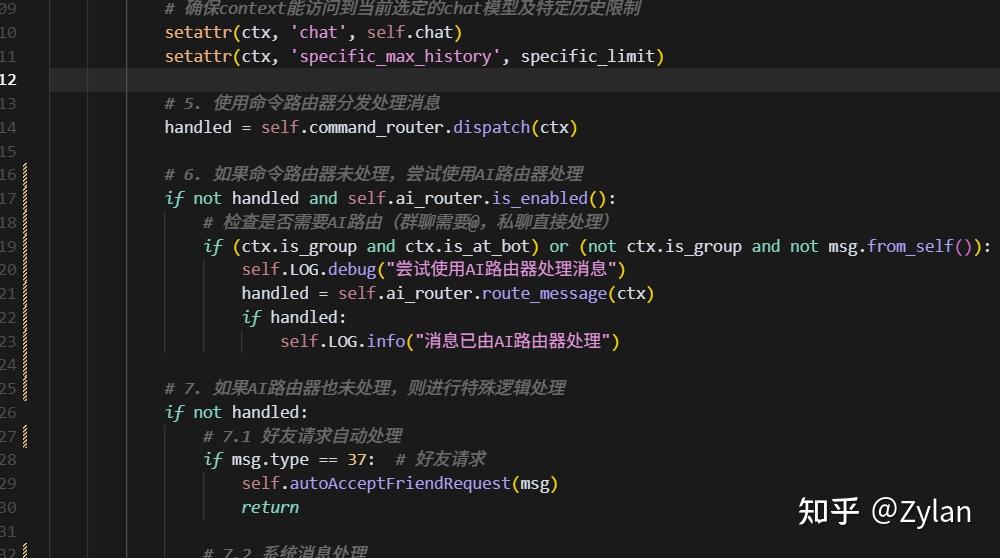
而且它也贴心地帮我进行了测试,测试完之后把程序打开了,我哭死: