音声文字起こしデータの価値は、近年のLLMの進歩により向上していると感じています。例えば、LLMに会議の文字起こしを要約させることで会議録画を全て視聴する必要がなくなる、といった新しい利用方法が出てきたためです。
しかし、社内会議では専門用語や人物、部署といった固有名詞が含まれるハイコンテクストな会話が多く、Copilotによる会議要約でうまく文字起こしされないケースを経験された方も多いのではないでしょうか。
Azure Speech ServicesのCustom Speech機能では音声認識モデルをカスタマイズし、専門用語や特定の音声環境に最適化して文字起こしの精度を向上させることができます。
Custom Speechでカスタム可能な音声モデル カスタマイズに使用するデータセットの種類 プレーンテキスト 構造化テキスト 音声+トランスクリプト モデルのトレーニング 前提 Custom Speechプロジェクトの作成 テスト用データセット トレーニング用データセット データセットの登録 トレーニングの実行 テストの実行 テスト結果の確認 まとめ Custom Speechでカスタム可能な音声モデルCustom Speechでは、Whisper Large V2と、Whisperの登場以前から存在する従来型の音声認識モデルのカスタマイズが可能です。
WhisperモデルはBatch音声テキスト変換にしか対応していませんが、従来モデルはリアルタイム音声テキスト変換もサポートしています。
今回は従来型モデルをカスタマイズしてみましょう。
カスタマイズに使用するデータセットの種類日本語の場合、従来型モデルの認識精度向上に利用できるデータセットには以下の種類があります。*1
プレーンテキストひとつのテキストファイルに、文章を書き連ねるだけで作れるデータセットです。一行がひとつの発話(一文)になるようにします。
ドメイン固有の単語や語句の認識率向上につながるとのことです。
構造化テキストこちらもテキストファイルのみのデータセットですが、Markdown形式で構造化されたドキュメントにすることで、より効率的にデータセットを構成することができます。
例えば、同様の使い方をする複数の製品名を特定のエンティティとしてまとめて定義することで、重複した例文をいくつも作成する必要がなくなります。
音声+トランスクリプト音声と手動で作成した文字起こしを組み合わせたデータセットです。
作成の手間はかかりますが、最もトレーニングの効果が期待できます。雑音やノイズ、アクセントなど特定の性質を持つ音声の文字起こし精度を向上させる場合に有効です。また、カスタマイズしたモデルの精度を確認する場合にも必要になります。
トレーニングに利用する場合、ひとつの音声ファイルあたり40秒以内(Whisperモデルをトレーニングする場合は30秒以内)に収める必要があるので注意が必要です。
モデルのトレーニングそれでは、実際にモデルのトレーニングとテストを行ってみましょう。
前提以下の手順は、有効なAzureサブスクリプションにAzure Speech Services(音声サービス)がデプロイされていることを前提にしています。
Custom Speechプロジェクトの作成Speech Studioを開き、「Custom Speech プロジェクトの開始」からプロジェクトを作成します。

プロジェクト名と音声認識モデルを対応させる言語を選択します。今回は日本語のカスタムモデルを作成します。

Custom Speechでカスタマイズしたモデルのテストには、音声+トランスクリプト形式のデータセットが必要です。
今回は、JBSウェブサイトから以下の文章を読み上げ、録音したものを使用します。
外部のデータに基づいて AI チャットアシスタントが回答を返す RAG の機能を提供。今お使いの SharePoint Online のコンテンツを指定したり、Azure Data Lake Storage Gen2 にドキュメントファイルを置くだけで、アイプリシティが経営情報、人事情報、一般情報など権限に応じて社内の情報に基づいて回答します。
www.jbs.co.jp
音声ファイルは、ffmpegを用いて次のコマンドでw形式に変換しました。
ffmpeg -i aipli3.m4a -ar 16000 -ac 1 -sample_fmt s16 aipli3.wテキストファイルはタブ区切りで、以下のようにしています。
音声ファイル名\tトランスクリプト
wファイルとtxtファイルを適当なフォルダに格納し、zip圧縮します。
トレーニング用データセット今回は、プレーンテキスト形式のデータセットのみでトレーニングを行います。
先ほどのウェブページより、テスト用データセットに含まれない部分をテキスト形式で、一行一文になるように加工し保存しました。
データセットの登録トレーニングで利用するプレーンテキストと、テストで利用する音声+トランスクリプトのデータセットを登録します。
先ほど作成したCustom Speechプロジェクトの画面から、データのアップロードを選択します。

テキストを選択し、次に進みます。

テキストファイルをドラッグアンドドロップ、またはファイルを参照して次に進みます。

データセットの名前を入力し、次に進みます。

内容を確認し、問題なければ保存して「閉じる」を選択します。

音声+トランスクリプトのzipファイルも、最初の選択画面以外は同様の手順です。これでデータセットの登録が完了しました。

実際にプレーンテキストによるトレーニングを実施し、カスタムモデルを作成します。左ペインからカスタムモデルのトレーニングページを開きます。

新しいモデルのトレーニングを選択します。

トレーニングするベースラインモデルを選択し、次に進みます。

先ほどアップロードしたテキスト形式のデーセットを選択し、次へ進みます。
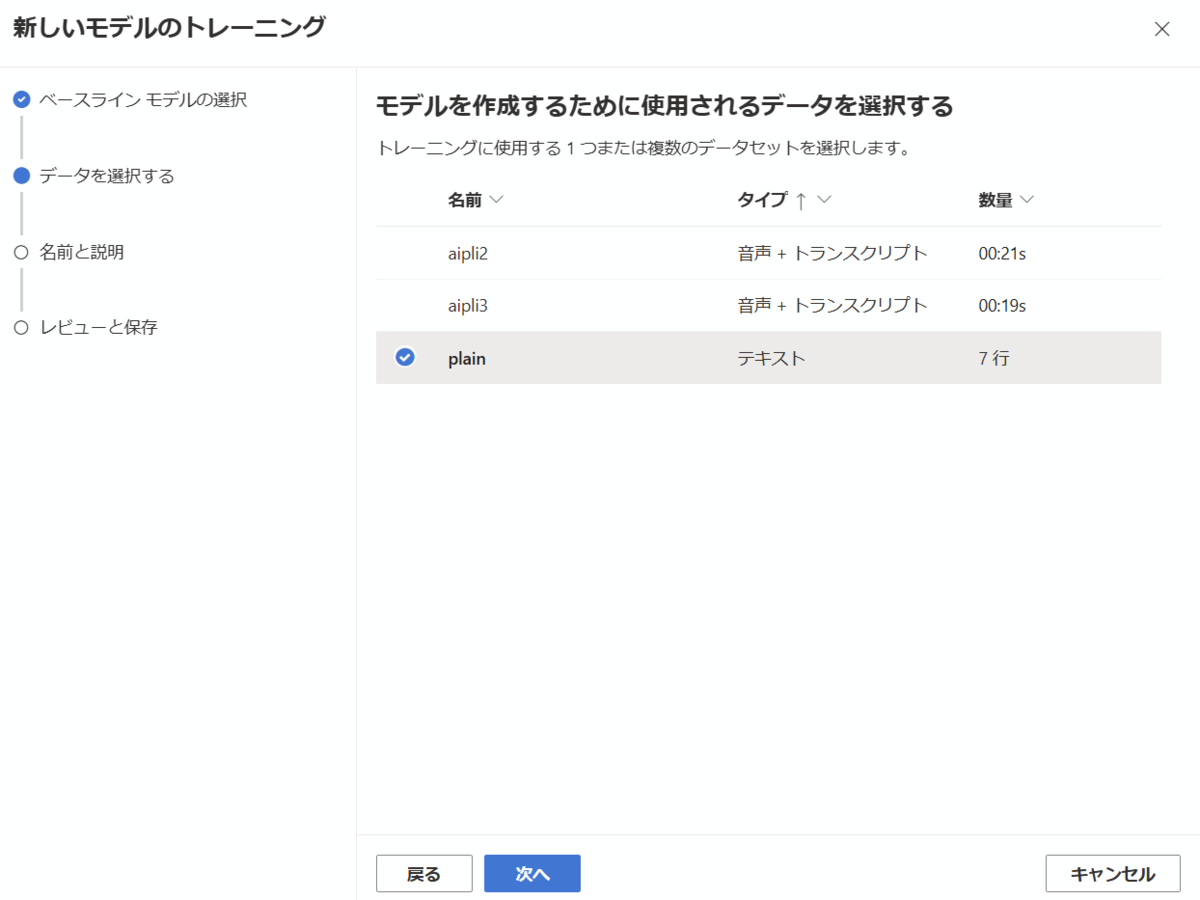
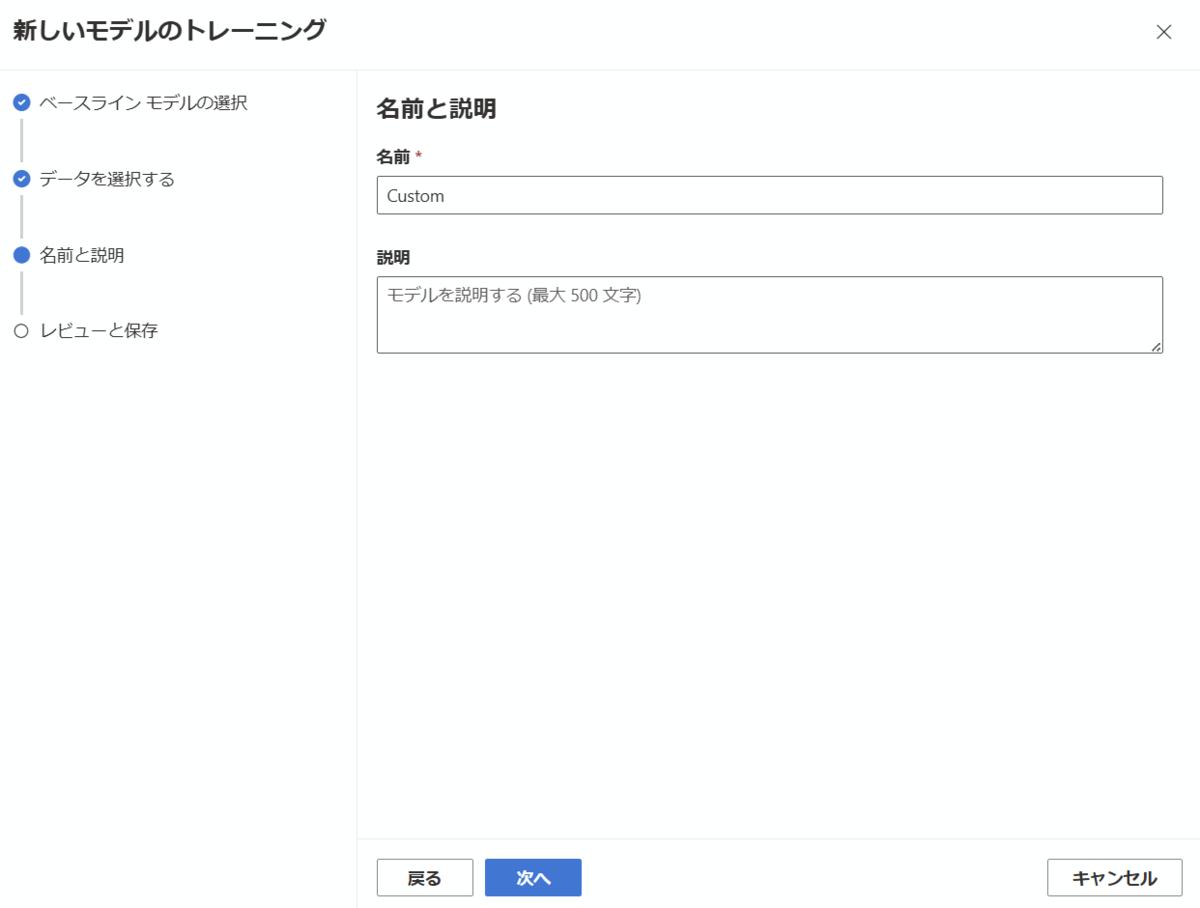
カスタムモデルの名前を入力し、次へ進みます。
内容を確認し、問題なければ保存して閉じるを選択します。
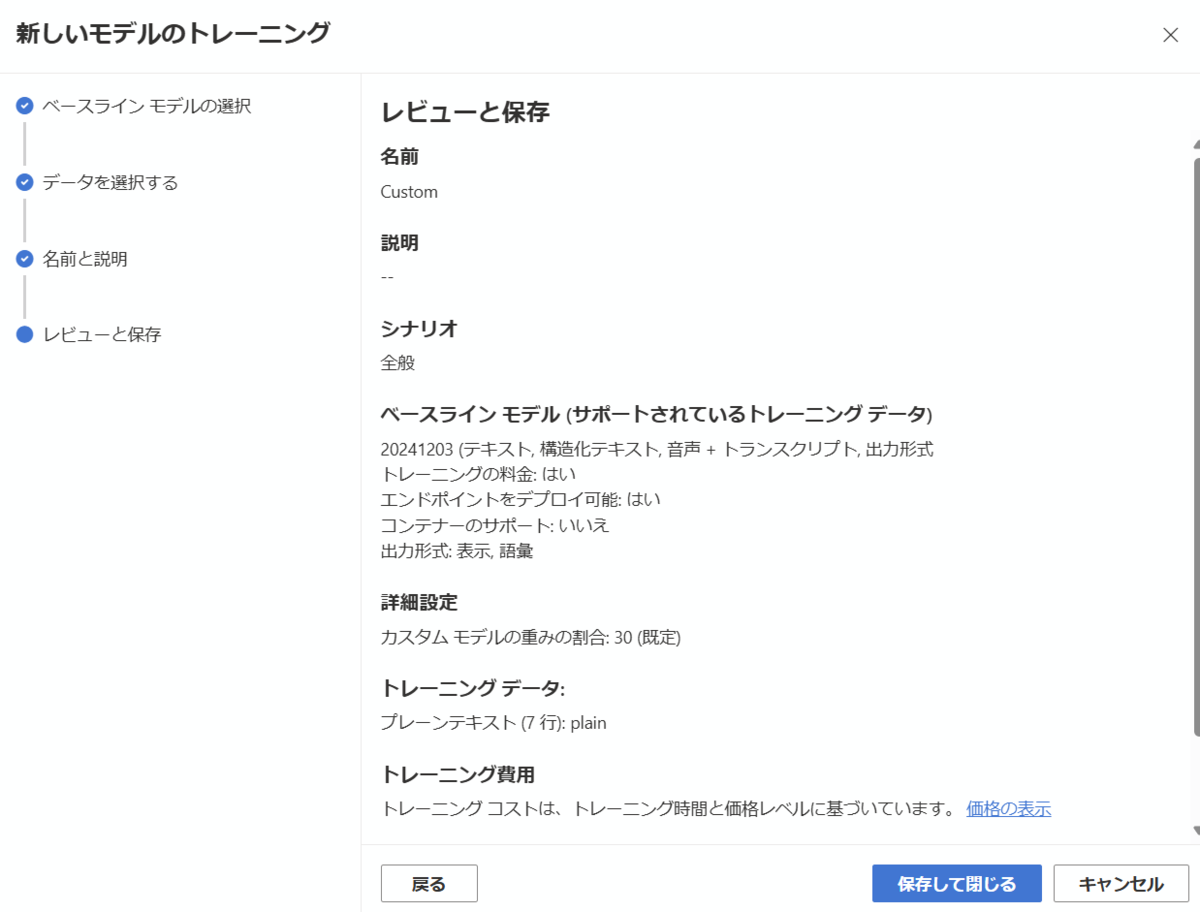
カスタムモデルのトレーニングには数分程度以上かかります。状態が処理中から成功になったら、次の手順に進みます。
テストの実行左ペインからテストモデルを開きます。

新しいテストを作成するを選択します。

精度の評価を選択し、次に進みます。

先ほどアップロードした音声+トランスクリプト形式のデータセットを選択し、次へ進みます。

カスタマイズしたモデルとベースラインモデルの精度を比較するため、モデル1とモデル2にそれぞれを選択し、次に進みます。
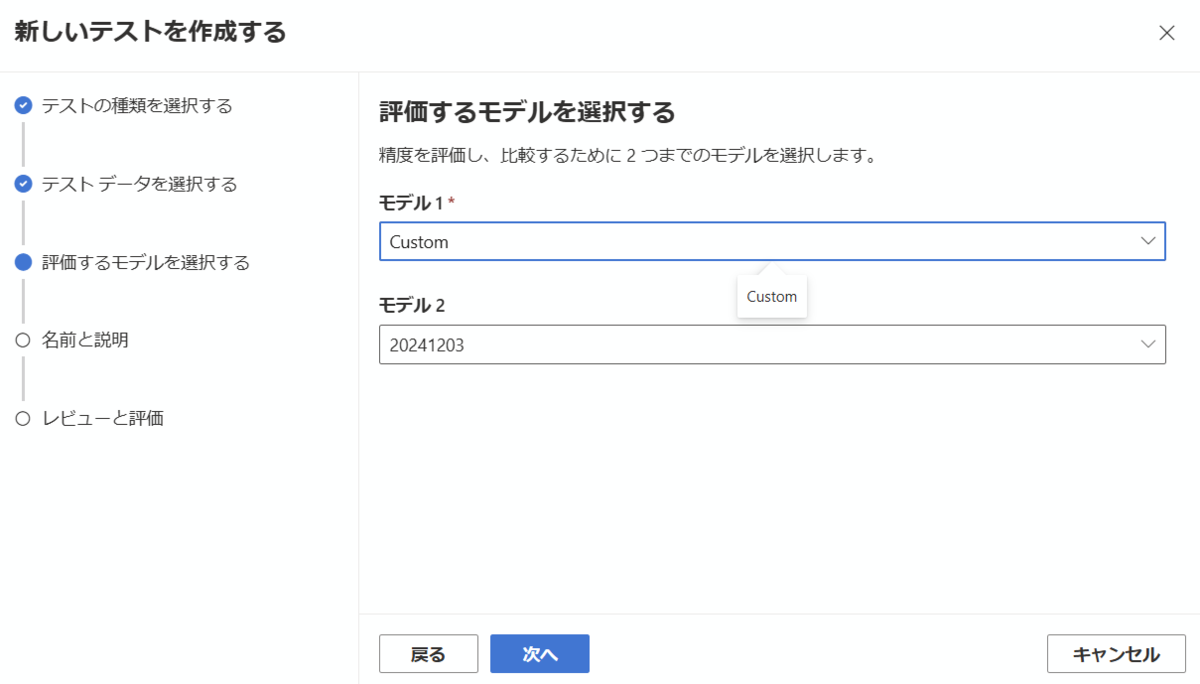
テスト名を入力し、次に進みます。
内容を確認し、問題なければ保存して閉じるを選択します。

モデルのテストには数分程度以上かかります。状態が処理中から成功になったら、次の手順に進みます。
テスト結果の確認テスト結果を確認すると、単語誤り率(WER)が1.5%程度改善していました。

詳細に内容を確認すると、azure datalake storageのdataの部分がベースラインモデルではカタカナで文字起こしされていたのに対し、カスタムモデルでは英語表記で文字起こしされるようになっていました。

「アイプリシティチャット」やAzureの専門用語などの認識精度が改善することを想定していましたが、元々の認識精度が良かったためにあまり変化が感じられない結果となってしまいました。
しかし、今回のように少ないプレーンテキストによるトレーニングだけでも、音声認識に変化があることが確認できました。
JBSではプレーンテキストだけでなく、構造化テキストや音声+トランスクリプトによるカスタムモデル作成もご支援可能です。ご興味がある方はご気軽にこちらからお問い合わせください。
*1:Whisperモデルは音声+トランスクリプト形式のデータセットでトレーニング可能です。詳細は公式ドキュメントをご参照ください。
執筆担当者プロフィール
渡邊 洋一(日本ビジネスシステムズ株式会社)
Data&AI本部 ラボセンター所属 インフラエンジニア→クラウド、機械学習等
担当記事一覧